Cronbach-alfa kiszámítása SPSS programcsomagban
Cronbach-alfa kiszámítása SPSS programcsomagban
E mutató kiszámítási módjai változatosak, az SPSS programcsomagban több lehetőség is mutatkozik meghatározására. Ezek közül egyet fogunk bemutatni a már megismert adatfájlon.
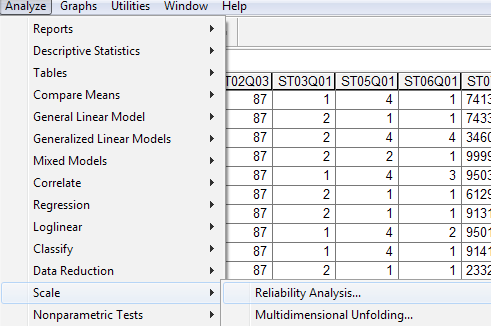
Az Analyze menüpont Scale alpontjában található a Reliability Analysis… lehetőség. Ennek elindítása után a következő képernyőképet láthatjuk:
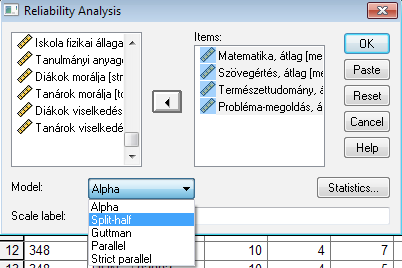
Válasszuk ki a 4 teljesítmény-változót (mintha iskolai év végi átlagot akarnánk számolni, a felmért diákok matematika-, szövegértés-, természettudomány- és problémamegoldás- teljesítményét szeretnénk egy „kompetencia”-skála értékben összegezni).
A modellek közül az Alpha eljárás az alapként beállított eljárás. A Split-half metódus akkor alkalmazott leginkább, amikor több, jellemzően nagyszámú itemet szeretnénk egy skálában egyesíteni (miután a pszichológiai skáláknál ez egy jellemző eset, így ezt az outputot mutatom be, bár jelen helyzetben a 4 itemre való tekintettel elegendő lenne az Alpha-modell alkalmazása is). A „Statistics” opció választása után az alábbi párbeszédpanelt láthatjuk:
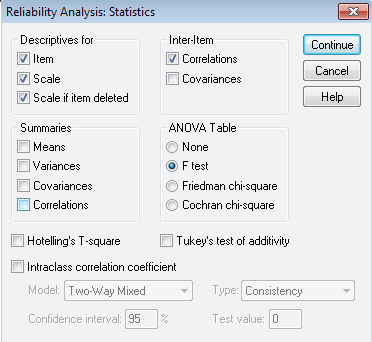
A leíró statisztikák általában hasznunkra lehetnek, így ezek mindegyikét érdemes kikérni. Amennyiben mégis úgy éreznénk, hogy feleslegesek pl. az itemek leíró statisztikái, úgy elhagyhatók, de a harmadik, Scale if item deleted opciót akkor is végeztessük el a programmal, ugyanis innen derül ki az, hogy a skála-változónk miként viselkedne, ha egyes itemeket elhagynánk belőle. Így azt is láthatjuk, hogy mely itemek inkonzisztensek a skálánkon belül.
Az itemek közötti korreláció (inter-item korreláció) mindenképpen fontos abból a szempontból, hogy alacsony inkonzisztencia-szint mellett az itemeknek ne csak az előzőekben már mért, össz-skálához való viszonyát lássuk, hanem az esetleges klikkesedésüket, vagy egy-egy item többihez viszonyított, nem megfelelő viselkedését.
Az ANOVA teszt segítségével megállapíthatjuk, hogy a skálánkban szereplő itemeink esetén a mért egyedeink között, vagy esetleg egy-egy egyed esetében – a skálákon belül – láthatók-e jelentősebb eltérések, variabilitások.
RELIABILITY
/VARIABLES=mean_m mean_r mean_sc mean_pr
/SCALE(‚ALL VARIABLES’) ALL/MODEL=SPLIT
/STATISTICS=DESCRIPTIVE SCALE CORR ANOVA
/SUMMARY=TOTAL .