Diszkriminancia-analízis és k-középpontú klaszterezés az SPSS-ben
Diszkriminancia-analízis és k-középpontú klaszterezés az SPSS-ben
Mindkét eljárást a klasszifikációs módszerek között találjuk az Analyze menüpontban. A k-középpontú klaszterezés a K-means Cluster menüpont, míg a diszkriminancia-analízis a Discriminant részmenü alatt lesz megtalálható (de ezt még egyszer külön kiemeljük).
A korábbiakban a 2 morál- és 2 viselkedés-változó alapján készítettünk klasztereket. Most ismét ezt tesszük. Az iterációszámot – ahogy a ROPstatban is – be lehet állítani. Ezt jegyezzük meg, mert ha emiatt jelez nekünk a program, akkor tudnunk kell, hogy hol kell átállítani (megemelni) ezt a paramétert, hogy valóban stabil eredményekhez juthassunk. A klaszterek számát ne felejtsük el beállítani a korábbiakban bemutatott 3-ra.
Ahhoz, hogy utána ellenőrizni tudjunk, a Save lehetőségnél be kell állítani, hogy a klaszterhez tartozást minden egyedre elmentse a program – ez a változó meg fog jelenni a változólista végén.
QUICK CLUSTER
stmorale tcmorale studbeha teacbeha
/MISSING=LISTWISE
/CRITERIA= CLUSTER(3) MXITER(10) CONVERGE(0)
/METHOD=KMEANS(NOUPDATE)
/SAVE CLUSTER
/PRINT INITIAL.
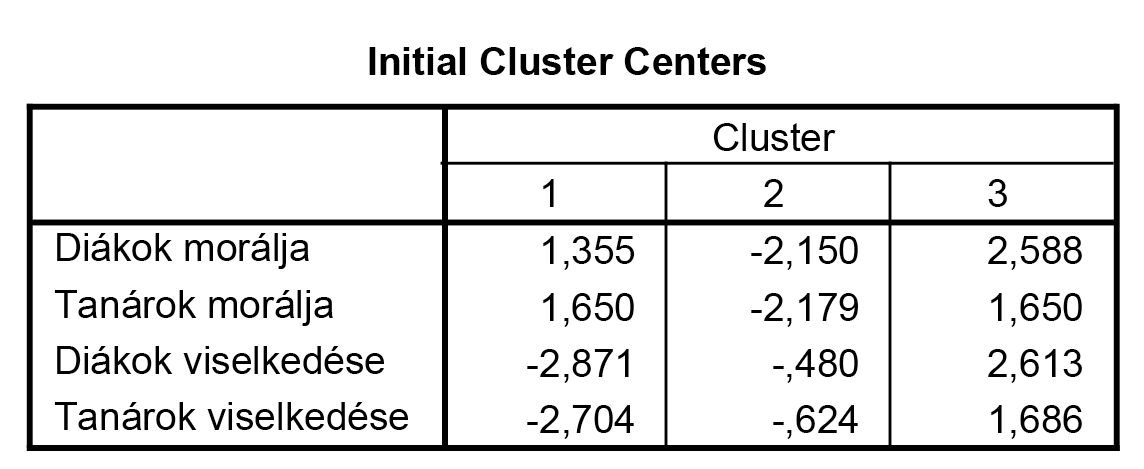
A kezdő klaszterközéppontok koordinátáját feltünteti a program (bár mi ezzel az információval nem nagyon fogunk semmit sem kezdeni). Ennek fényében mostantól csak azokat a táblázatokat mutatjuk majd be, melyek ahhoz kellenek, hogy az eredményeinket értelmezni tudjuk, illetve melyeknek hasznos értelmezése lehetséges.

A végső klaszter-középpontokat már korábban megnéztük, tehát túl sok új információval ez a táblázat sem szolgálhat már számunkra. Ismét megállapíthatjuk, hogy az első klaszterben a morál-változók magasak, míg a viselkedés-értékek alacsonyak. A kettes csoportban alapvetően alacsony, míg a hármasban magas értékek vannak. AZAZ: az előzőekhez képest most csak a klaszter SORSZÁMA változott, a tulajdonsága nem!
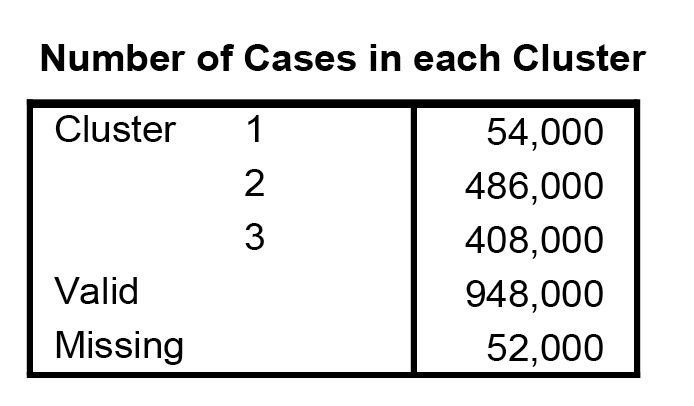
Ezt az esetszámok alapján le is tudjuk ellenőrizni. Lényegében a megoldás ugyanaz, csak a csoportok felsorolásának sorrendje változott meg.
Az eredményeket tehát diszkriminancia-analízis segítségével fogjuk értékelni, illetve ellenőrizni. Az eljárást a már említett helyen találjuk – de álljon itt most ismétlésképpen.
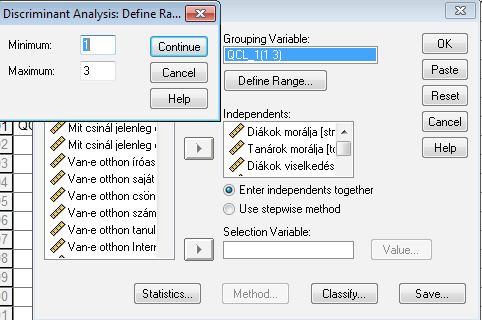
A csoportosító változónk az újonnan létrehozott klaszter-besorolást tartalmazó változónk lesz. Ne felejtsük el megadni, hogy a változónk (QCL_1) 1 és 3 közötti értékeket vehet fel, ezeket szeretnénk szeparálni, előállítani.
A független változók tehát változatlanul a klaszterezés alapjául is szolgáló változó-szettünk lesz.
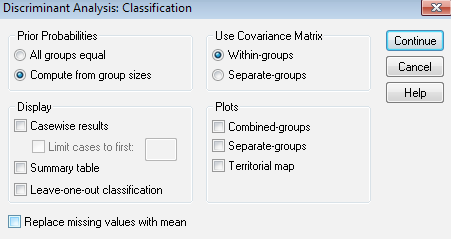
A klasszifikációnál figyeljünk arra, hogy a csoportok nem egyenlő esetszámúak, így a csoportok esetszámának meghatározását nekünk kell majd átállítani – így ezt az opciót kell választanunk az alapbeállításból!
Továbbá, hogy lehessen ellenőrizni az eredményeinket, az előrejelzést, illetve a gép által alkalmazott besorolást el kell mentenünk magunknak.
DISCRIMINANT
/GROUPS=QCL_1(1 3)
/VARIABLES=stmorale tcmorale studbeha teacbeha
/ANALYSIS ALL
/SAVE=CLASS
/PRIORS SIZE
/CLASSIFY=NONMISSING POOLED .
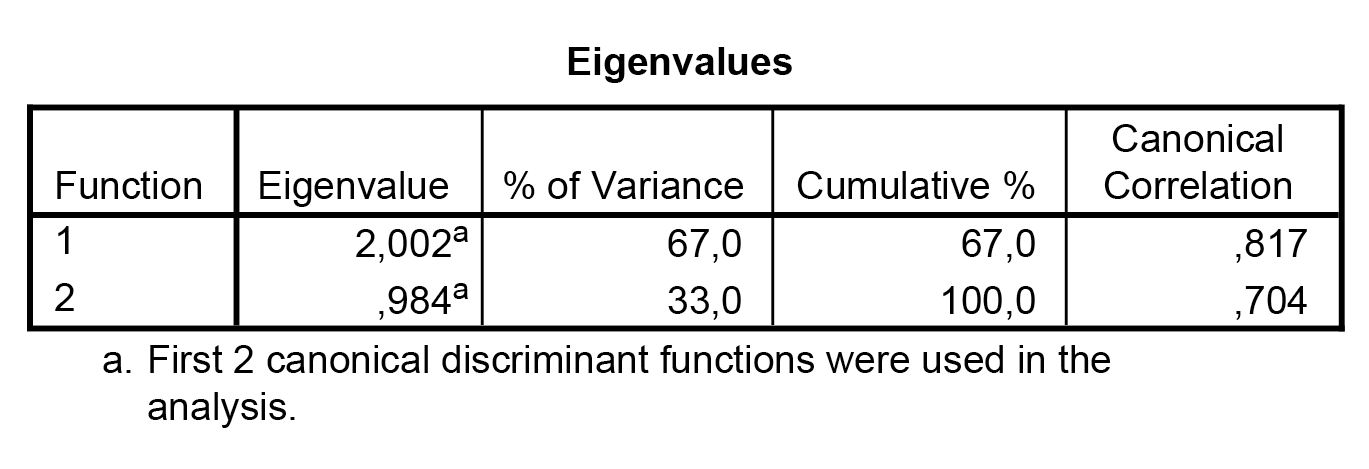
A sajátértékekből azt láthatjuk, hogy az érdemi információt az első vágás fogja tartalmazni (azaz az igazi eltérést, különbséget majd az első csoport leválasztása jelenti, a másik két csoport utána való diszkriminálása – elkülönítése – már nem hoz annyi többlet variancia-magyarázatot).
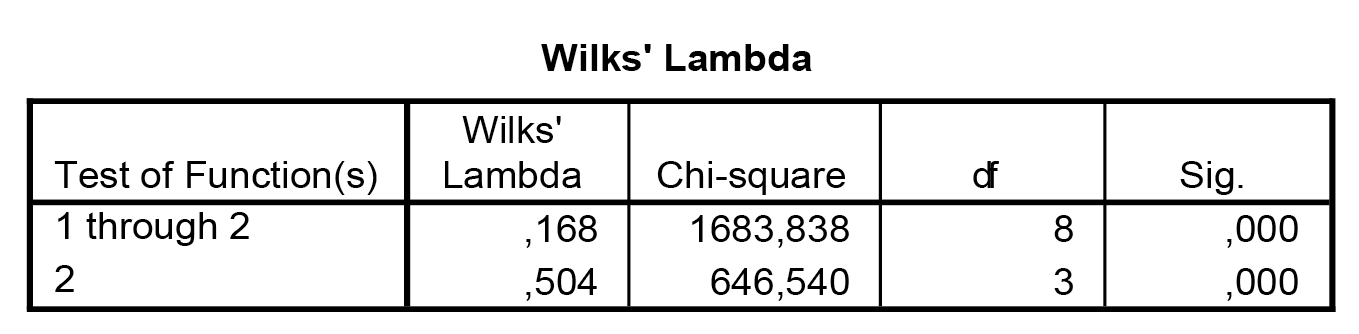
A Wilks-féle lambda mutató a diszkriminancia-analízis „determinációs együtthatója”, igazából annak inverze (lényegében a nem megmagyarázott variancia-arány). Minél alacsonyabb ez az érték, annál jobb a szeparációs képesség. Ne felejtsük el, hogy az egész csoportosítás magyarázó ereje 50% körül volt – ezt összességében tartja is a lambda alapján az eljárás. Azonban vegyük észre, hogy az első csoport levágása lényegesen nagyobb fegyvertényt jelent – hiszen ott van kisebb Wilks-lambda érték. Azonban mindkét érték szignifikáns, így az eredményeink is kellően reménykeltőek.
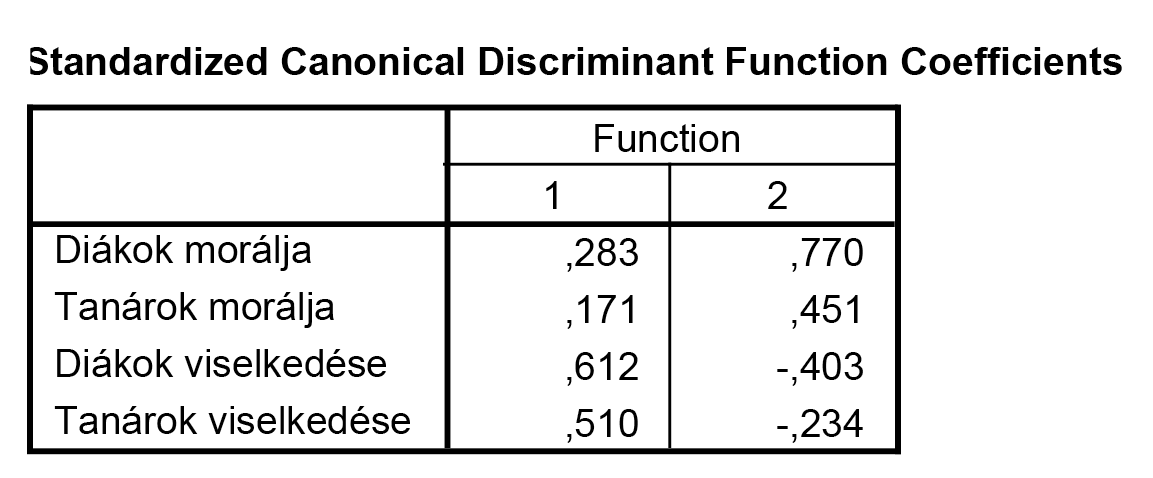
Amennyiben a diszkrimináló függvényeket szeretnénk felírni, úgy azok együtthatója (standardizált változók esetére) e táblázatban megtalálható. A felírás lényegében ugyanúgy történik, mint a lineáris regresszió esetében (azzal a különbséggel, hogy itt nincsen konstans tag a standardizálás következtében).
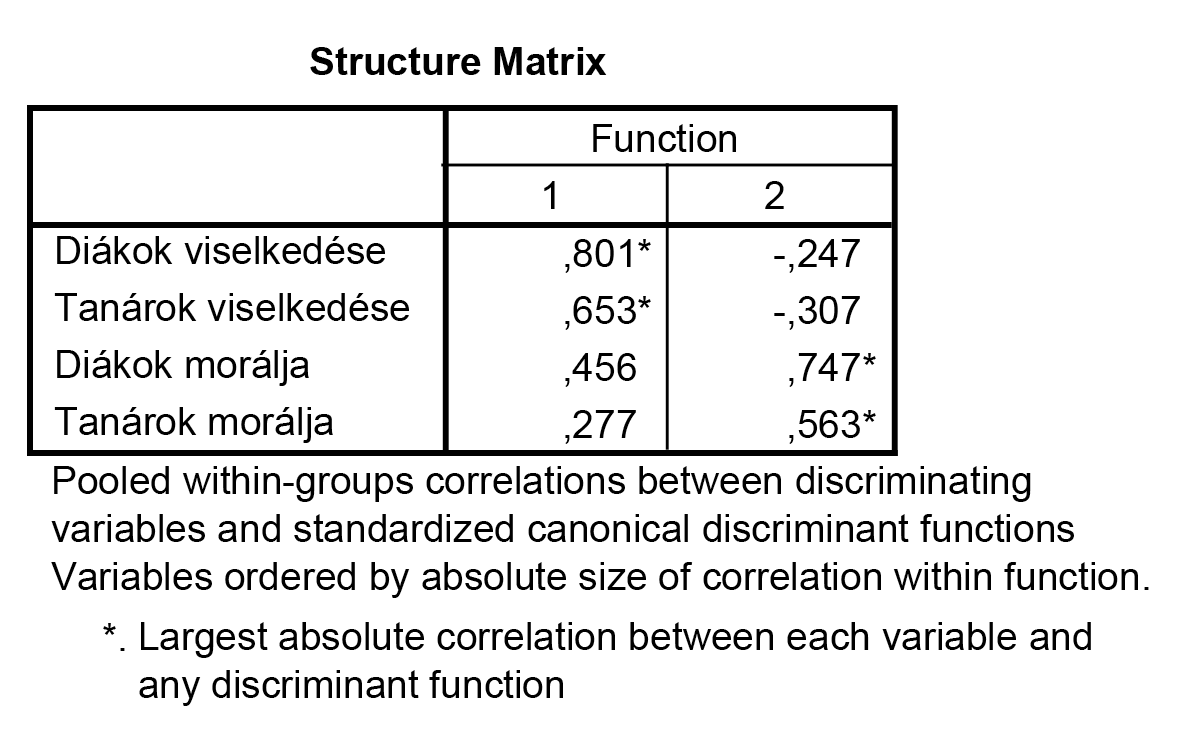
Látható, hogy az első diszkrimináló függvényt alapvetően a viselkedés, míg a másodikat a morál definiálja – a megcsillagozott értékek alapján tudjuk mindezt leolvasni.

A csoportokat a diszkriminálás utáni középpont-értékek alapján tudjuk legkönnyebben elvégezni. Ezek alapján (figyelembe véve azt is, hogy a függvényeket alapvetően mely változók jellemzik) elmondhatjuk, hogy az első csoportban alacsony a viselkedés-érték és magas a morál-, a második csoportban mindkét érték alacsony, és a harmadikban mindkét érték magas.
Ezek alapján már valóban reménykedhetünk, hogy a két módszer valóban ugyanazon eredményeket produkálja számunkra. Ezt egy kereszttáblás elemzéssel – az elmentett prediktív értékek alapján – könnyedén le is tudjuk ellenőrizni.
A kereszttáblás elemzések alapvetően a BA-képzés részét képezik, így itt sok magyarázatot nem szeretnénk már fűzni a mutatókhoz.
A két mentett változót (QCL_1; Dis_1) teszteljük, a köztük lévő kapcsolat meglétét és erejét szeretnék meghatározni – ezért alkalmazzuk a khi-négyzet statisztikát, és határozzuk meg a kontingencia-együtthatót is.
CROSSTABS
/TABLES=QCL_1 BY Dis_1
/FORMAT= AVALUE TABLES
/STATISTIC=CHISQ CC PHI
/CELLS= COUNT
/COUNT ROUND CELL .
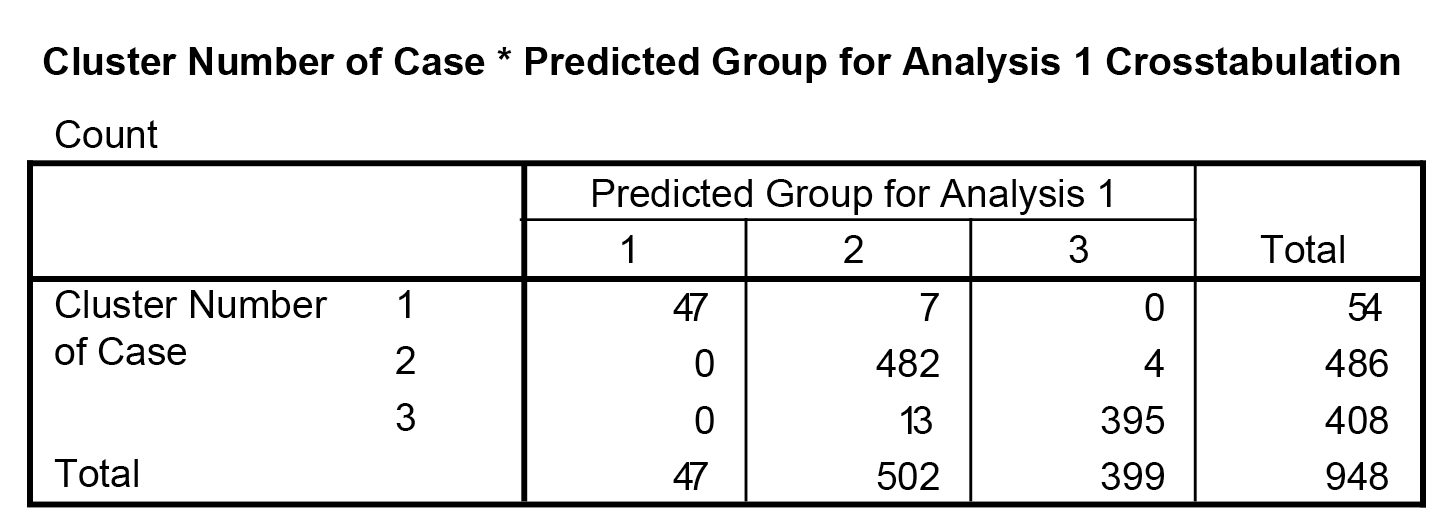
Megfigyelhető, hogy az 1-1, 2-2 és 3-3 pozíciókban vannak a magas értékek, azaz lényegében minden klasztert eltalált a diszkriminancia-analízis eljárása (az első klaszterben nem történt mellélövés), a többi klaszterben is igen csekély mértékű a hibás meghatározás aránya.
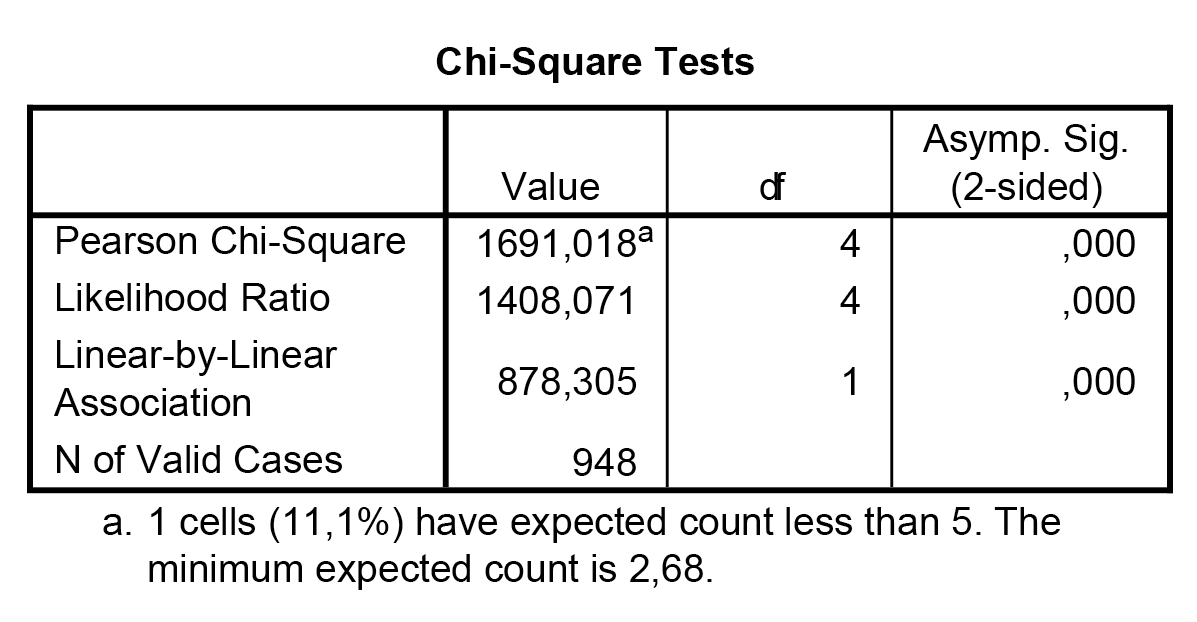
A khi-négyzet statisztika – ahogy a táblázat alapján azt várni is lehetett – szignifikáns kapcsolatot jelez. Azonban szeretnénk, ha ez a kapcsolat igen erősnek is mutatkozna, hiszen akkor elmondhatnánk, hogy valóban stabil klaszterezettséget vélünk felfedezni a mintánkban.
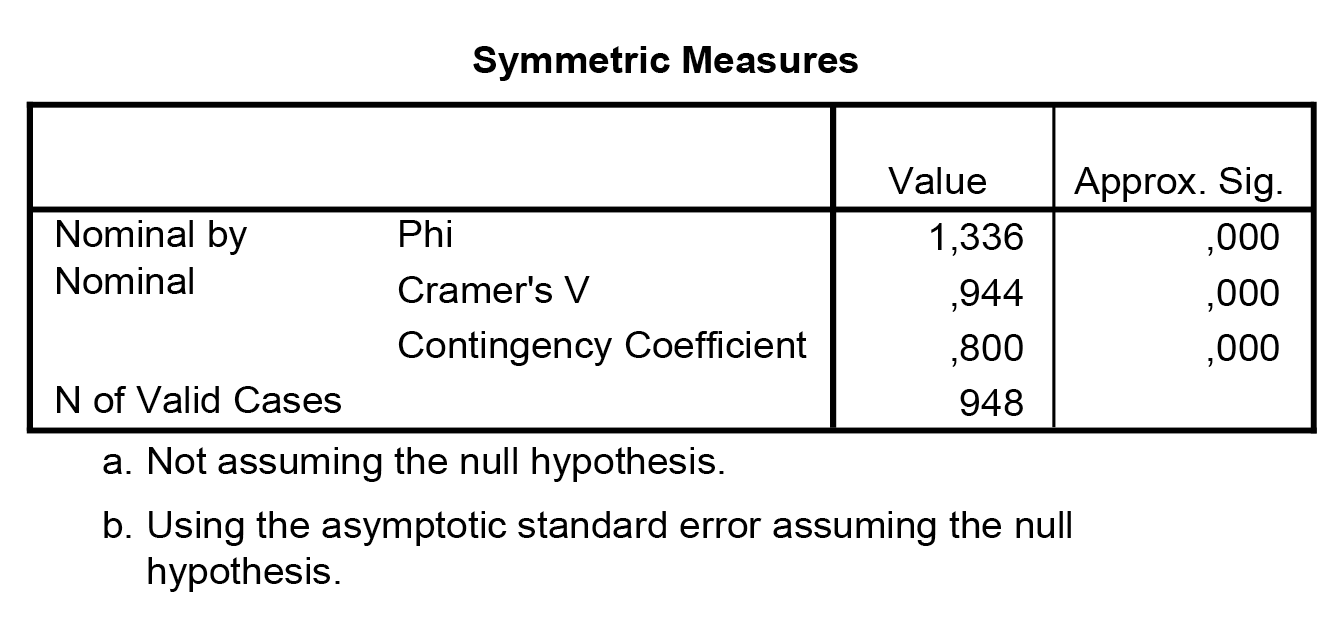
A kontingencia-együtthatónk közel 1-es értéke, mely természetesen (ezt már láttuk korábban) szignifikánsan különbözik 0-tól, azt mutatja, hogy erős összefüggés van a két módszer által adott besorolás, osztályozás között – így megállapíthatjuk, hogy a relokációs klaszterezés segítségével végzett besorolás stabilnak tekinthető, hiszen azt egy másik módszer segítségével lényegében reprodukálni tudtuk.