DUMMY változók alkalmazása
DUMMY változók alkalmazása
Az elemzést továbbra is az OECD PISA adatokon mutatom be, hogy ne kelljen újabb változókat górcső alá vennünk. Az elemzésben DUMMY változókat fogunk használni, ezzel bővítve tehát a lineáris regresszió használhatóságát.
A DUMMY változók minden esetben bináris változók. Ez azt jelenti, hogy csak 2 értéket vehetnek fel, hagyományosan 0-t és 1-et. Az elemzéseink során általában akkor alkalmazzuk ezt az eljárást, ha nominális skálázású változókat szeretnénk az elemzéseinkbe bevonni. Ekkor ugyanis a program csak kódokat lát, melyeknek nincsen jelentése – azonban amint bevonjuk a lineáris regressziós modellbe, máris jelentést adunk ezeknek a kódoknak, sőt: az eredeti változónkat intervallum-skálázású új változóvá változtatjuk, mely tulajdonsággal nem rendelkeznek – de ezt a gép nem tudja, nem is tudhatja.
Egy gondolatkísérlet erejéig tekintsük azt az extrém esetet, hogy a matematika és szövegértés teljesítményt úgy szeretnénk vizsgálni, hogy a modellbe beépítjük, hogy a vizsgált személy milyen irányítószám alatt lakik.
Természetes, hogy ez egy számszerű adat, azonban alapvetően nominális jellegűnek tekinthető, hiszen lényegében városokat, vidékeket, kerületeket vagy kerületrészeket takar. Sőt: hatása is lehet, hiszen a fővárosi diákok teljesítménye általában magasabb a vizsgált kutatás alapján, így azok az irányítószámok, melyek fővárosi helyet jelölnek, elvileg magasabb értékeket hordoznak. Azonban azt is látnunk kell, hogy a számszerű kódok közötti összefüggés valójában nominális összefüggéseket takar – a számszerű összefüggést mi magunk látjuk bele a modellbe – ha az egyáltalán kimutatható. Valójában nem számszerűsíthető a kapcsolat.
A teljes irányítószám-lista dekódolása helyett vegyünk egy kicsit kisebb, de még mindig a területi viszonyokat tükröző változót: tekintsük változónak a település típusát. Az alábbi kódokat alkalmazhatjuk (továbbra is maradva a gondolatkísérlet mezsgyéjén).
|
Kód |
Település típusa |
|
1. |
Főváros |
|
2. |
Vidéki város |
|
3. |
Község |
Vegyük észre, hogy az irányítószámnál említett számszerűségi probléma nem szűnt meg: amennyiben ezt a változót alkalmazzuk az elemzésben, ugyanazon hibába fogunk esni. Ez azt jelenti, hogy a számszerű kódok nem jelölnek valójában semmifajta számszerű összefüggést a település típusa között. A főváros lényegében semmilyen paraméterében nem „harmada” a községeknek – holott a kódjaikban ez az érték szerepel. Ennek kiküszöbölése azonban lényegesen könnyebb ennél a változónál, mint az az irányítószám esetén lett volna (lévén kevesebb kód van).
Elkészítjük az alábbi két DUMMY változót (a korábban elküldött segédanyagban ennek módját már ismertettem).
|
Kód |
DUMMY 1, Településtípus, Főváros |
|
1 |
Főváros |
|
0 |
Nem főváros |
|
Kód |
DUMMY 2, Településtípus, Vidéki város |
|
1 |
Vidéki város |
|
0 |
Nem vidéki város |
Vegyük észre, hogy nincsen szükségünk harmadik kódra. Ekkor ugyanis az alábbi, két számból álló kódrendszer jön létre:
|
Kódok (D1,D2) |
Jelentés |
|
(1,0) |
Főváros |
|
(0,1) |
Vidéki város |
|
(0,0) |
Község |
A (0,0) kód (azaz mindkét DUMMY – D1, D2 – értéke 0) valóban azt jelenti, hogy se nem vidéki városi, se nem fővárosi diákról van szó, és miután minden diákot egyértelműen be tudunk sorolni valamely csoportba és csak egy csoportba, így a (0,0) kód esetén nyilvánvalóan községi lakosról van szó. Ezért a DUMMY változók megalkotásánál minden esetben elegendő a kódszámoknál eggyel kevesebb változó létrehozása (bár tagadhatatlan, hogy az értelmezést és az interpretálhatóságot olykor megkönnyíti az összes kódra létrehozott változók használata).
Azt is figyeljük meg, hogy ha az eredeti változó helyett ezt a két DUMMY változót alkalmazzuk, akkor jól értelmezhető modellt fogunk nyerni – és az eredeti információmennyiségünk is megmarad. Tegyük fel, hogy az alábbi modellt nyerjük:
matematika = 32 + 0,9 • szöveg + 12 • D1 + 7 • D
Az így megalkotott új DUMMY változók segítségével kifejezhető a matematika és szövegértés, illetve iskolatípus közötti összefüggés, mely a fenti egyenlettel írható le. Az egyenletben lévő szövegértés és két DUMMY változó (D1 és D2) együtthatóit a következő módon értelmezhetjük.
A matematika-teljesítményhez a szövegértés-változó minden pontjának elmozdulása 0,9 pont elmozdulást ad hozzá (amennyiben a másik két változó változatlan).
Továbbá amennyiben az első DUMMY változó 0-ról 1 értékre változik (hiszen csak 2 érték van), azaz fővárosi diákról van szó, 12 pontos többletet jelent a számára (azonos szövegértés-szint mellett).
Ha vidéki városi a diák (D2 = 1), akkor ezt a 12 pontot nem kapja meg (hiszen akkor D1 = 0), azonban helyette 7 pontos többletet kap – hiszen D2 együtthatója 7 – (szintén azonos szövegértés-szinten). Azt is látjuk ráadásul, hogy a fővárosi vagy vidéki városi diákok kikhez képest kapják ezeket a többletpontokat: mindkét DUMMY változó értékének 0 volta esetén nem jár többletpontszám – ők a községekben lakó diákok.
Vizsgáljuk meg egy konkrét példán egy másik DUMMY változók technikai hátterét.
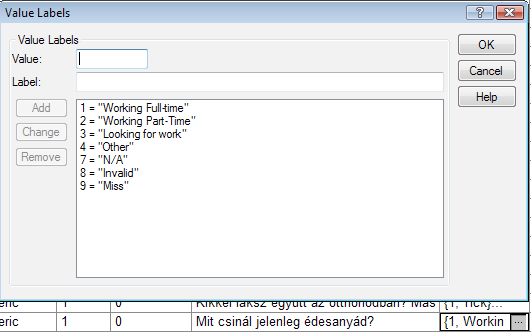
A „Mit csinál jelenleg édesanyád?” kérdésre adható válaszok lehetséges értékei 1 és 4 közötti kódokon vannak nyilvántartva. Ezen kívül a hiányzó értékeknek is fenn van tartva 3 kód (7, 8 és 9). Ezeket most újrakódoljuk, és DUMMY változók segítségével megpróbáljuk ezt a változót is bevonni az elemzésbe annak érdekében, hogy megtudjuk: a matematika és a szövegértés viszonyára milyen hatással van az édesanya jelenlegi foglalkozása, illetve pontosabban annak munkaideje.
Az új kódutasítás az alábbi lesz (recode paranccsal ennek létrehozását már elviekben ismerjük, tudjuk):
|
Új kód |
Jelentés |
|
1 |
Teljes állás |
|
2 |
Részállás |
|
3 |
Nincsen rendszeres munkaviszony |
E fenti változó tehát az összes kódból az első kettőt használja, minden mást a 3-as új kódban jelöl, hiányzó értékeket és nem normál munkaviszonyt egyaránt. E kódolás olyan szempontból mindenképpen jogosnak vehető, hogy ha minket a két hagyományos (teljes munkaidős vagy részmunkaidős) munkaviszony hatása érdekel, úgy a többi esetet nyugodtan kezelhetjük egy kalap alatt.
Természetesen ezt a változót nem kell létrehoznunk, hiszen egyből megalkothatjuk a két DUMMY változót is.
Ez a két változó (D1, D2) az alábbi kódokkal jön létre:
|
Kód |
DUMMY 1, Anya munka, Teljes állás |
|
1 |
Teljes állás |
|
0 |
Nincs teljes állás |
|
Kód |
DUMMY 2, Anya munka, Részállás |
|
1 |
Részállás |
|
0 |
Nincs teljes állás |
RECODE
ST05Q01
(1=1) (ELSE=0) INTO d1 .
VARIABLE LABELS d1 ‚Édesanya mit dolgozik, DUMMY, teljes állás’.
EXECUTE .
RECODE
ST05Q01
(2=1) (ELSE=0) INTO d2 .
VARIABLE LABELS d2 ‚Édesanya mit dolgozik, DUMMY, részállás’.
EXECUTE .
Most, hogy létrehoztuk a megfelelő változókat, már bevonhatjuk azokat az elemzésünkbe. Ennek utasítása – az alábbi:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT mean_m
/METHOD=ENTER mean_r d1 d2 .
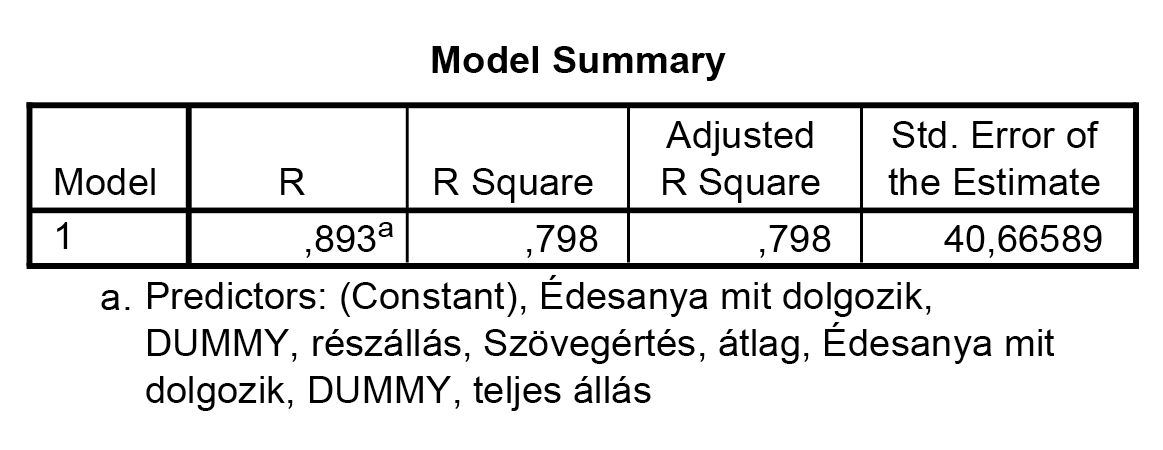
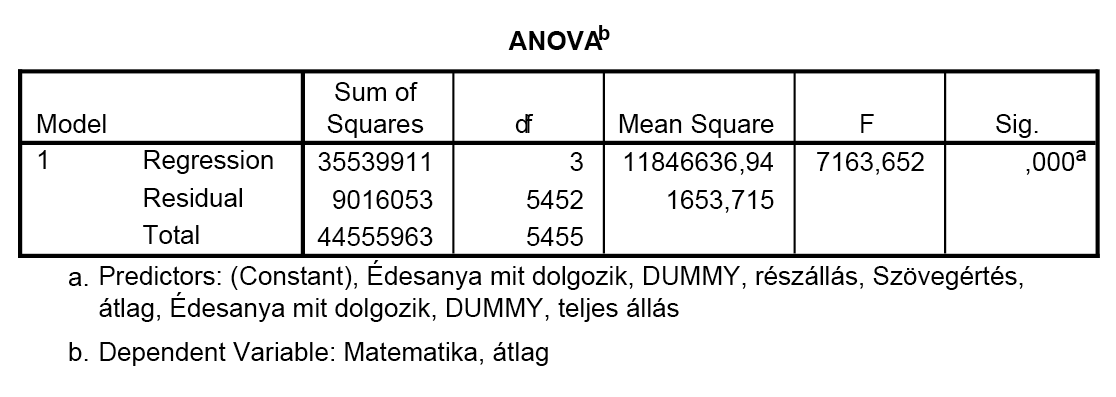
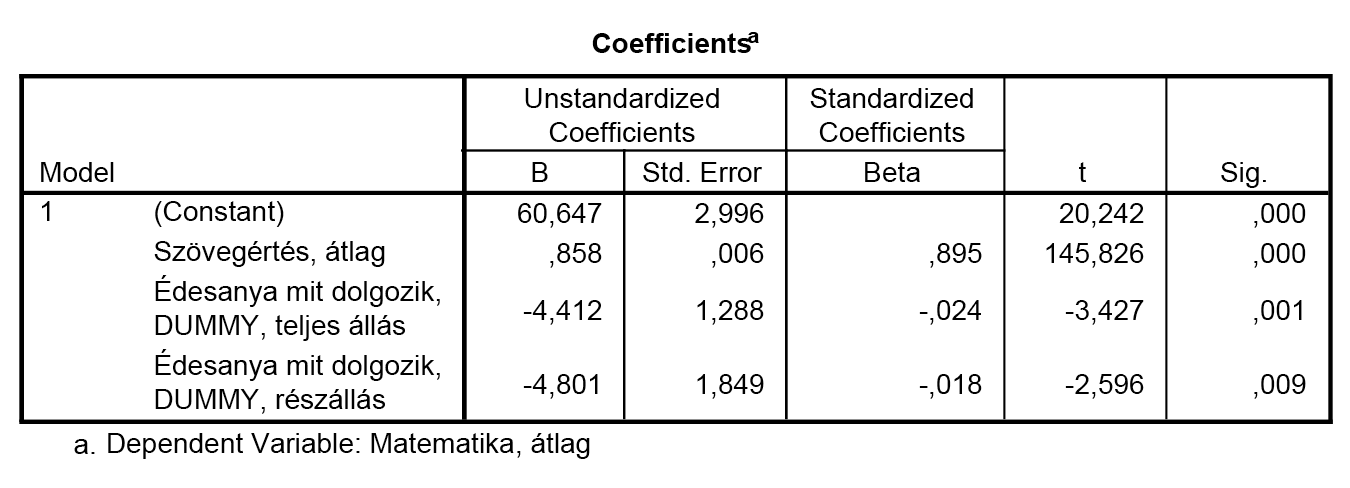
Mit jelentenek az egyenletben található különböző együtthatók? A szövegértés előtti 0,858-as szorzó azt mondja, hogy ha minden értéket fixen tartunk, akkor a szövegértésben tapasztalható 1 pontos eltérés ugyanolyan irányú, 0,858 pont eltérést eredményez a várható matematika-teljesítményben.
A teljes állás DUMMY változónál látható, szignifikánsan nem 0 – tehát relevánsan jelen lévő – együttható azt üzeni, hogy amennyiben az édesanya nincsen otthon, teljes állásban dolgozik, úgy a vizsgált diákoknál, azonos szövegértés-szinten –4,4 pontos differenciát látunk (azaz akinél az édesanya teljes állásban dolgozik, annak valamivel több, mint 4 ponttal gyengébb a várható teljesítménye).
A részállás DUMMY változónál lévő –4,801-es szorzó, azaz a D2 együtthatója szintén ezt mondja: a részállásban dolgozó édesanya gyermeke várhatóan majdnem 5 ponttal teljesít gyengébben matematikából a többi részpopuláció átlagához képest.
A standardizált együtthatókból azt is leolvashatjuk, hogy miután a szövegértésnek van a legnagyobb abszolút értéke, így e változónak van a legnagyobb szerepe a matematika-teljesítmény előrejelzésében. A t-értékek és a szignifikanciák azt mutatják, hogy minden bevont változó érvényes – azaz mindegyik bevont változó együtthatója szignifikánsan különbözik 0-tól.
Természetesen ez nem ad teljes elemzést a problémáról. Valójában az itt lévő szignifikáns különbségek megállapítását ANOVA elemzéssel célszerű végrehajtani. Azonban ha modellezésre van szükségünk, melyben diszkrét, nominális változókat szeretnénk figyelembe venni, úgy e technika segítségével megnyugtató megoldást tudunk adni.
Sajnálatosan így tudjuk meg azt, hogy a részállásban és a főállásban dolgozó édesanyák azonos szövegértés-szinten lévő gyermekeinek várható matematika-teljesítményében van-e eltérés. Azt viszont tudhatjuk, hogy mind a teljes állásban, mind a részállásban dolgozó édesanyák – azonos szövegértés-szinten lévő – gyermekei szignifikánsan gyengébben teljesítenek az egyéb elfoglaltsággal (pl. otthon lévő édesanya) bíró édesanyák gyermekeinél.