2.1. DISZKRÉT VÁLTOZÓK ESETE – Gyakorisági elemzés a NEM-változóra
2.1. DISZKRÉT VÁLTOZÓK ESETE – Gyakorisági elemzés a NEM-változóra
Vegyük tehát az első esetet, illetve a harmadik esetnek azt a részét, amikor a változónknak a gyakorisági eloszlását szeretnénk bemutatni, pl. arra vonatkozó hipotéziseink miatt.
A vizsgálat lépései – ROPstat-ban
A ROPstat programcsomagban minden leíró statisztikát az Alapok (egymintás elemzések) menüpontban találhatunk meg.
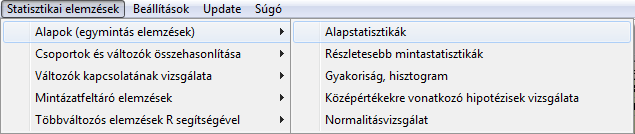
Az első két menüpont a kvantitatív változók esetén alkalmazandó, míg a gyakoriság, hisztogram menüpont alkalmazható mind kvantitatív, mind kvalitatív változókra (de kvalitatív változókra csak ez).
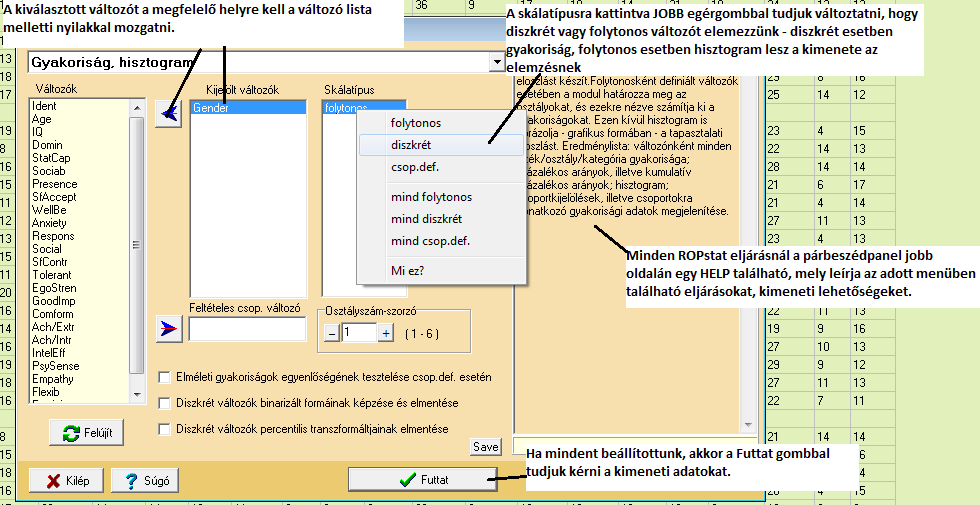
Ha minden beállításunk megfelelő volt, akkor az alábbi output az eredmény:
|| A ROPstat olyan statisztikai programcsomag, amely a standard
egyváltozós módszerek teljes repertoárja
|| mellett gazdag választékát nyújtja a robusztus technikáknak és
az ordinális skálájú változókkal végezhető
|| elemzéseknek. A ROPstat megkülönböztetett figyelmet szentel a
mintázatfeltáró eljárásoknak is.
|| A ROPstat szerzői:
|| - Prof. Dr. Vargha András, Károli Gáspár Református Egyetem
Pszichológiai Intézete, Budapest
|| - Bánsági Péter matematikus mérnök, Budajenő
|| Konzultáns: Prof. Dr. Lars R. Bergman, Stockholm University,
Department of Psychology
Az input fájl neve: C:\_vargha\ropstat\dat\CPI.msw
Gyakoriság, hisztogram
A beolvasott összes eset száma: 94
VÁLTOZÓ: Gender (Gender of subjects)
| Érték | Gyak | % | Kum% | |
| 1 | 16 | 17,0 | 17,0 | |======== |
| 2 | 78 | 83,0 | 100,0 | |============================================ |
| Össz | 94 |
Értelmezésre ebben az esetben nem sok szükség van. A továbbiakban az output elején található, programot bemutató sávot nem fogom másolni. Az outputok elején látható mindig az input fájl neve (ezt is szisztematikusan ki fogom hagyni).
A következő sor mindig az alkalmazott eljárás, majd esetszám. Végül a számunkra most érdekes eredmények: a NEM-változónak két kódja van (1: férfi, 2: nő), gyakoriságok (16 férfi és 78 nő van a mintában), mely százalékos megoszlásban 17-83%. A kumulált százalékok a folytonos változók esetén játszanak inkább szerepet, hiszen ennek jelentése, hogy hányan tartózkodnak az adott értéknél nem nagyobb sávban (pl. hány legfeljebb 35 éves van a mintában.
A vizsgálat lépései – SPSS-ben
Miután a ROPstat és az SPSS outputja érdemben nem különbözhetnek egymástól, ezért csak az elemzés lépéseit mutatom be, illetve az output különböző részeit magyarázom el – a műhelymunka-megfogalmazás nem fog változni.
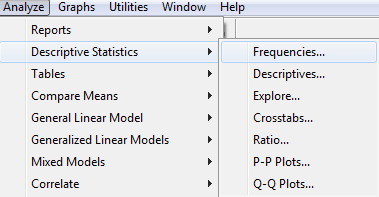
Az SPSS-ben minden elemzés az Analyze menüpontban található. A leíró statisztikákat értelemszerűen a leíró statisztikáknál (Descriptive Statistics) kell keresni, azon belül a diszkrét változókra vonatkozó gyakorisági elemzés a Frequencies… almenüben kapott helyet.
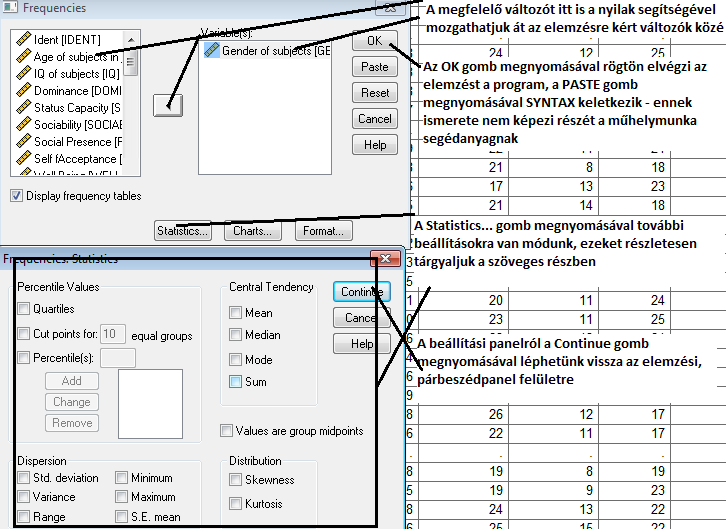
A gyakoriságokon túl az alábbi lehetőségeink vannak – tartva a fenti struktúrát a táblázatos leírásban is.
|
Percentilisek. Alapvetően
folytonos változóknál fontos mutatók, melyek jelentése: a
populációban várhatóan mely érték alatt / felett
helyezkedik el a populáció adott százaléka. A kvartilisek
esetén 25%-ot keresünk, megadhatóak olyan kérések, hogy
pl. 10 egyenlő részre hogyan vághatná el a populációt
(dekádok), illetve a percentilisek esetén akármely érték
megadható (például 20-30-50-80 beállítással). Műhelymunkában ritkán használt, leíró statisztikáknál sem túl gyakori. |
Középértékek. Alapvető jelentőségű mutatók – mindenfajta változóra használhatjuk, azonban ha a fenti felsorolás harmadik esete áll fenn, azaz olyan változóval dolgozunk, mint pl. az osztályzatok, akkor itt spórolhatunk egy kis időt magunknak. Mert ezeket a statisztikákat egy másik menüpontban is elérhetjük, az output lényegében megegyezik – azonban akkor egy elemzési részt időben megtakaríthatunk. Kikérhető (sorrendben) az átlag, medián és módusz (az összeg lényegében nem használatos). Műhelymunkákban gyakori, lényegében mindenfajta változó bemutatásánál alkalmaznunk kell valamilyen középérték meghatározást. |
|
Leíró statisztikai mutatók. Az első oszlopban a szóródási mutatók kaptak helyet, sorrendben: szórás, variancia (szórásnégyzet) és a terjedelem (maximum és minimum különbsége). A második oszlopban a minimum és a maximum, illetve az átlag standard hibája, míg az utolsó oszlopban az alaki mutatók találhatóak – sorrendben a ferdeség (skewness) és a csúcsosság (kurtosis). Műhelymunkában szintén gyakori az alkalmazásuk, de ez is folytonos változókra vonatkozik általában, így szintén nem e menüpontból érdemes elérni. |
|
Az output itt kicsit másként néz ki, mint a ROPstat programcsomagban. Rögtön táblázatos formában kapunk mindent – mely szerencsés, ha nem kerül megszerkesztésre. Ezért is élek majd a fejezet végén egy általános javaslattal az outputokat illetően.

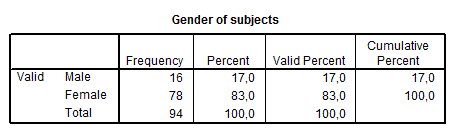
Tartalmát tekintve egyetlen többlet található. A valid százalékok jelentéséhez tudnunk kell, hogy vannak olyan helyzetek, amikor bizonyos kérdésekre a megkérdezettek nem tudnak vagy nem akarnak válaszolni. A valid százalék azt mutatja meg, hogy a válaszadók között milyen a százalékos megoszlása a különböző kategóriáknak – míg a százalék a teljes mintát figyelembe veszi.
Minden egyéb megegyezik a ROPstat adataival. Az első táblázatban láthatjuk, hogy hány fős a minta, illetve a Missing értékeknél látnánk, ha valaki nem válaszolt volna a fenti kérdésre.
A második táblázatban először a címkék (férfi-nő), majd sorban a gyakoriság, százalék, valid százalék és kumulatív százalék értékek szerepelnek.
Műhelymunkabeli megfogalmazás
A műhelymunkákban tehát a diszkrét változók elemzésére alapvetően a gyakorisági elemzéseket használhatjuk – azonban nem mindegy, hogy ezeket hogyan fogalmazzuk meg. Ábraszerkesztést szándékosan nem mutatok be, hiszen erre vonatkozóan sok lehetőségünk van – érdemes lehet kísérletezni. Általánosan az oszlop- vagy sávdiagram típus kereshető, vagy a kördiagramok. Az SPSS grafikai lehetőségei mellett az EXCEL is bevethető, illetve bármely más program, amiben kényelmesen tudunk ábrákat szerkeszteni.
Megfogalmazás
A felmérés során 94 válaszoló adatait sikerült megszerezni. A mintában 16 férfi és 78 nő volt. Az adatokat táblázatos formában is összefoglalom:
|
NEM |
Gyakoriság |
Százalékos megoszlás |
|
Férfi |
16 |
17% |
|
Nő |
78 |
83% |
|
ÖSSZESEN |
94 |
100% |
Egy műhelymunkában tehát nem kell túlmisztifikálni a minta bemutatását, hiszen a lényegi részek majd a hipotéziseink lesznek – így az egyszerű, átlátható megfogalmazásokra kell törekedni. Röviden, pontosan definiáljunk mindent – mutassuk be a mintánkat, de ne ez legyen a fő statisztikai mozgatórugója a dolgozatunknak.
JAVASLAT
Bátran használjunk saját formátumot, nyugodtan szerkesszük át a programok által adott outputokat saját magunk számára könnyen értelmezhető, átlátható formába. AZ EREDETI OUTPUTOKAT MINDIG ŐRIZZÜK MEG, akár csatolmányként, mellékletként a dolgozathoz is lehet fűzni – ez mindig a helyzettől függ, hogy milyen formában kell ezeket tárolni.